Photo-z Server
Tutorial Notebook 2 - Training Sets
Contact author: Julia Gschwend
Last verified run: 2024-Jul-22
Introduction
Welcome to the PZ Server tutorials. If you are reading this notebook for
the first time, we recommend not to skip the introduction notebook:
0_introduction.ipynb also available in this same repository.
Imports and Setup
from pzserver import PzServer
import matplotlib.pyplot as plt
%reload_ext autoreload
%autoreload 2
# pz_server = PzServer(token="<your token>", host="pz-dev") # "pz-dev" is the temporary host for test phase
For convenience, the token can be saved into a file named as
token.txt (which is already listed in the .gitignore file in this
repository).
with open('token.txt', 'r') as file:
token = file.read()
pz_server = PzServer(token=token, host="pz-dev") # "pz-dev" is the temporary host for test phase
Product types
The PZ Server API provides Python classes with useful methods to handle particular product types. Let’s recap the product types available:
pz_server.display_product_types()
| Product type | Description |
|---|---|
| Spec-z Catalog | Catalog of spectroscopic redshifts and positions (usually equatorial coordinates). |
| Training Set | Training set for photo-z algorithms (tabular data). It usually contains magnitudes, errors, and true redshifts. |
| Validation Results | Results of a photo-z validation procedure (free format). Usually contains photo-z estimates (single estimates and/or pdf) of a validation set and photo-z validation metrics. |
| Photo-z Table | Results of a photo-z estimation procedure. If the data is larger than the file upload limit (200MB), the product entry stores only the metadata (instructions on accessing the data should be provided in the description field. |
Training Sets
In the context of the PZ Server, Training Sets are defined as the
product of matching (spatially) a given Spec-z Catalog (single survey or
compilation) to the photometric data, in this case, the LSST Objects
Catalog. The PZ Server API offers a tool called Training Set Maker for
users to build customized Training Sets based on the Spec-z Catalogs
available. Please see the companion Jupyter Notebook
pz_tsm_tutorial.ipynb for details.
Note 1: Commonly the training set is split into two or more subsets for photo-z validation purposes. If the Training Set owner has previously defined which objects should belong to each subset (trainining and validation/test sets), this information must be available as an extra column in the table or as clear instructions for reproducing the subsets separation in the data product description.
Note 2: The PZ Server only supports catalog-level Training Sets. Image-based Training Sets, e.g., for deep-learning algorithms, are not supported yet.
Mandatory column: * Spectroscopic (or true) redshift - float
Other expected columns * Object ID from LSST Objects Catalog -
integer * Observables: magnitudes (and/or colors, or fluxes) from
LSST Objects Catalog - float * Observable errors: magnitude errors
(and/or color errors, or flux errors) from LSST Objects Catalog -
float * Right ascension [degrees] - float * Declination
[degrees] - float * Quality Flag - integer, float, or
string * Subset Flag - integer, float, or string
Training Sets can be uploaded by users on PZ Server website or via the
pzserver library. Also, they can be created as the spatial
cross-matching between a given Spec-z Catalog previously registered in
the system and an Object table from a given LSST Data Release available
in the Brazilian IDAC by the PZ Sever’s pipeline “Training Set Maker”
(under development). Any Training Set built by the pipeline is
automatically registered as a regular user-generated data product and
has no difference from the uploaded ones.
train_goldenspike = pz_server.get_product(9)
Connecting to PZ Server...
Done!
train_goldenspike.display_metadata()
| key | value |
|---|---|
| id | 9 |
| release | None |
| product_type | Training Set |
| uploaded_by | gschwend |
| internal_name | 9_goldenspike_train_data_hdf5 |
| product_name | Goldenspike train data hdf5 |
| official_product | False |
| pz_code | |
| description | A mock training set created using the example notebook goldenspike.ipynb available in RAIL's repository. Test upload of files in hdf5 format. |
| created_at | 2023-03-29T19:12:59.746096Z |
| main_file | goldenspike_train_data.hdf5 |
Display basic statistics
train_goldenspike.data.describe()
| mag_err_g_lsst | mag_err_i_lsst | mag_err_r_lsst | mag_err_u_lsst | mag_err_y_lsst | mag_err_z_lsst | mag_g_lsst | mag_i_lsst | mag_r_lsst | mag_u_lsst | mag_y_lsst | mag_z_lsst | redshift | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 62.000000 | 62.000000 | 62.000000 | 61.000000 | 61.000000 | 62.000000 | 62.000000 | 62.000000 | 62.000000 | 61.000000 | 61.000000 | 62.000000 | 62.000000 |
| mean | 0.038182 | 0.016165 | 0.018770 | 0.188050 | 0.054682 | 0.021478 | 24.820000 | 23.384804 | 24.003970 | 25.446008 | 22.932354 | 23.074481 | 0.780298 |
| std | 0.036398 | 0.010069 | 0.013750 | 0.193747 | 0.115875 | 0.014961 | 1.314112 | 1.381587 | 1.387358 | 1.269277 | 1.540284 | 1.400673 | 0.355365 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 50% | 0.028309 | 0.013390 | 0.016660 | 0.133815 | 0.034199 | 0.018540 | 25.069970 | 23.748506 | 24.470215 | 25.577029 | 23.293384 | 23.514185 | 0.764600 |
| 75% | 0.049576 | 0.024650 | 0.025802 | 0.238859 | 0.063585 | 0.032557 | 25.705486 | 24.488654 | 24.985225 | 26.263284 | 23.993010 | 24.165944 | 0.948494 |
| max | 0.198195 | 0.036932 | 0.065360 | 1.154073 | 0.909230 | 0.051883 | 27.296152 | 24.949645 | 26.036958 | 28.482391 | 27.342151 | 24.693132 | 1.755764 |
8 rows × 13 columns
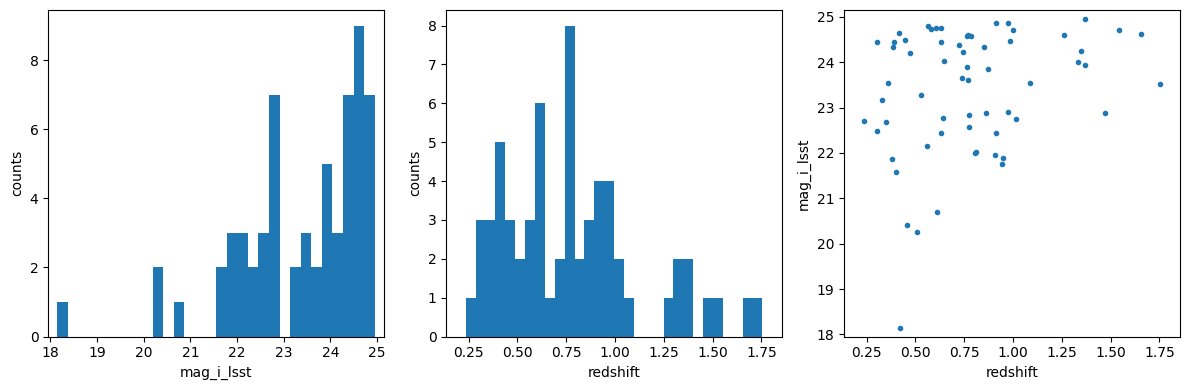
The training set object has a very basic plot method for quick visualization of catalog properties. For advanced interactive data visualization tips, we recommend the notebook DP02_06b_Interactive_Catalog_Visualization.ipynb from Rubin Observatory’s DP0.2 tutorial-notebooks repository.
train_goldenspike.plot(mag_name="mag_i_lsst")
Users feedback
Is something important missing? Click here to open an issue in the PZ Server library repository on GitHub.